Abstract
Unifying speech, sound, and music generation in one model is hindered by tradeoffs between fidelity, end-to-end training, in-context conditioning, and variable-length synthesis that no current paradigm fully resolves. To address this challenge, we present AudioCALM, a universal audio generation framework that extends autoregressive (AR) next-token prediction from discrete tokens to continuous audio latents: a thin flow-matching head replaces the softmax to predict rectified-flow velocities at each position, and a block-causal AR-Flow attention pattern produces arbitrary-length output. Joint training of multiple audio generation tasks faces an asymmetric text–audio mismatch: speech transcripts align to specific time spans and demand tight, time-aligned attention, whereas sound and music captions describe only overall semantics and rely on diffuse, holistic attention; mixing the two disproportionately degrades sound and music generation. We address this asymmetry at two levels: a data reformulation strategy that unifies all three tasks under a single description-style conditioning interface, and a novel architecture Asymmetric Mixture-of-Modality-Experts (A-MoME), which adds a dedicated residual expert for speech while sound and music share the backbone, incurring no inference overhead on non-speech inputs. Experimental results demonstrate that AudioCALM matches modality-specific state-of-the-art and outperforms prior unified baselines on speech, sound, and music generation benchmarks.
1Method
A single causal Transformer autoregresses over fixed-size blocks of continuous audio latents. A flow-matching head replaces the softmax; a block-causal AR-Flow attention pattern enables streaming arbitrary-length output; an asymmetric speech-only residual expert captures the tighter alignment that speech alone demands.
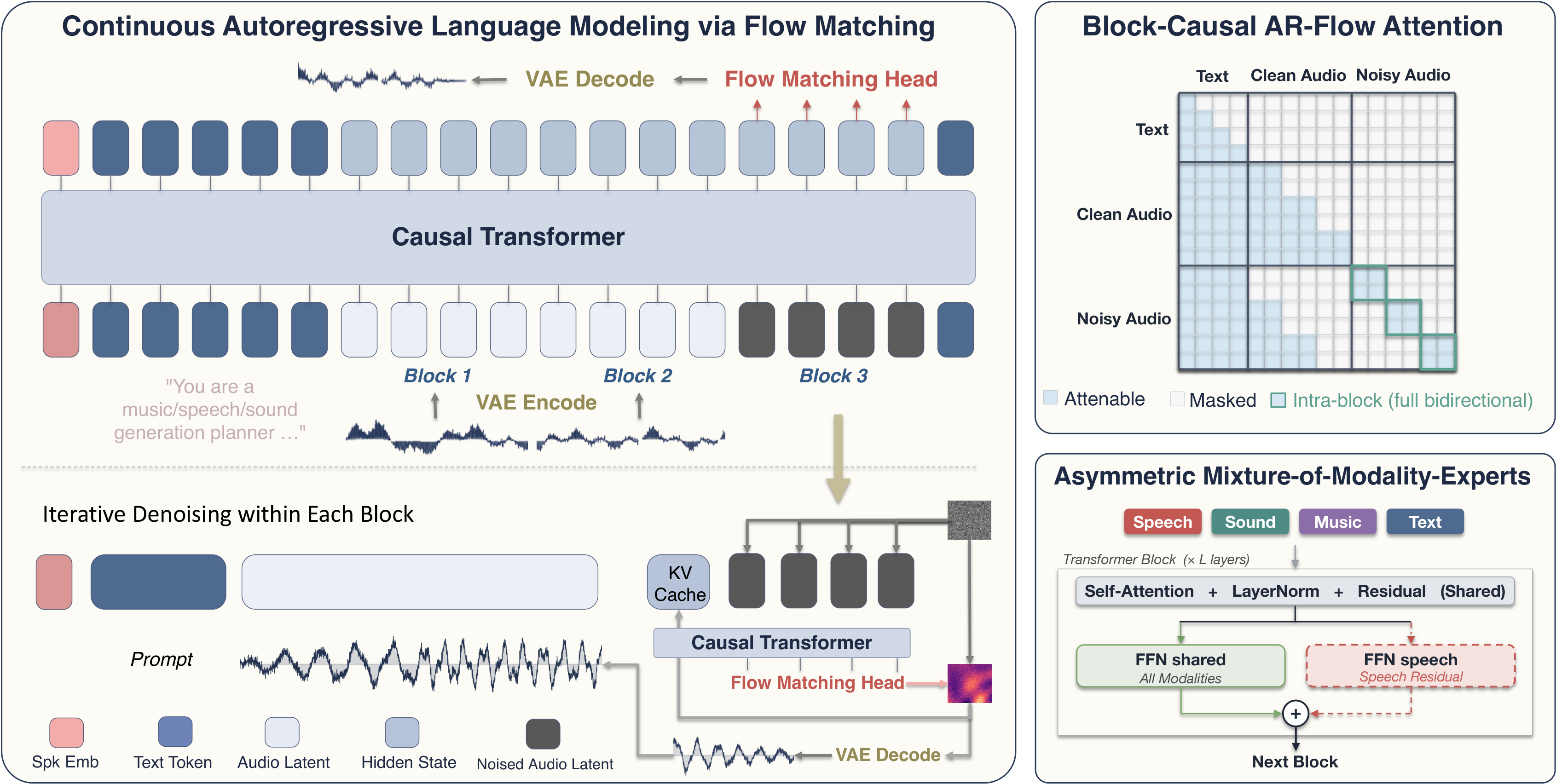
iContinuous AR LM
A flow-matching head replaces the softmax to predict rectified-flow velocities over VAE latents — keeping the LM interface while removing the codec bottleneck.
iiBlock-Causal AR-Flow
Causal across blocks, bidirectional within each block. Streams arbitrary-length audio under a single mask shared by training and inference.
iiiA-MoME
One residual FFN added on speech positions only — capacity follows the asymmetric text–audio mismatch with zero overhead on non-speech inputs.
2Zero-Shot Text-to-Speech Comparisons on LibriTTS
A reference utterance is prepended as the speaker prompt. AudioCALM is compared quantitatively against modality-specific TTS systems (F5-TTS, CosyVoice 3.0) and unified baselines (UniAudio, UniMoE-Audio, UniFlow-Audio, Ming-omni); full numbers are in the paper and summarized in the Results section below. Each card highlights the strongest baseline in each group — CosyVoice 3.0 (modality-specific) and Ming-omni (unified) — alongside Ground Truth and AudioCALM; the full baseline lineup is one click away under Compare baselines.
3Text-to-Sound Comparisons on AudioCaps
Held-out captions covering everyday acoustic events. AudioCALM is compared quantitatively against AudioLDM 2-Large, TangoFlux, Stable Audio Open, and the unified baselines (UniAudio, UniFlow-Audio, Ming-omni); full numbers are in the paper and summarized in the Results section below. Each card highlights the strongest baseline in each group — TangoFlux (modality-specific) and Ming-omni (unified) — alongside Ground Truth and AudioCALM; the full baseline lineup is one click away under Compare baselines.
4Text-to-Music Comparisons on Song-Describer
Held-out music captions spanning multiple genres. AudioCALM is compared quantitatively against MusicGen-Large, Stable Audio Open, and the unified baselines (UniAudio, UniMoE-Audio, UniFlow-Audio, Ming-omni); full numbers are in the paper and summarized in the Results section below. Each card highlights the strongest baseline in each group — Stable Audio Open (modality-specific) and UniMoE-Audio (unified) — alongside Ground Truth and AudioCALM; the full baseline lineup is one click away under Compare baselines.
5Results
Best per column in bold, second-best underlined. AudioCALM is a single model evaluated jointly across all three domains.
Metrics. WER (word error rate, lower is better) and SIM (cosine similarity between speaker embeddings of the generation and the reference, higher is better) measure speech intelligibility and speaker fidelity, respectively. FAD (Fréchet audio distance, lower is better) measures distributional fidelity. CLAP (text–audio cosine similarity, higher is better) measures prompt adherence. MOS is the subjective overall-quality score for speech (1–5, higher is better); MOS-Q and MOS-T are the subjective quality and text-relevance scores for sound and music (1–5, higher is better).
Text-to-speech
| Model | Benchmark A | Benchmark B | ||||
|---|---|---|---|---|---|---|
| WER ↓ | SIM ↑ | MOS ↑ | WER ↓ | SIM ↑ | MOS ↑ | |
| Modality-specific baselines | ||||||
| F5-TTS | 0.033 | 0.616 | 3.85 | 0.018 | 0.648 | 3.78 |
| CosyVoice 3.0 | 0.022 | 0.697 | 3.96 | 0.015 | 0.695 | 3.88 |
| Unified baselines | ||||||
| UniAudio | 0.120 | 0.265 | 3.30 | 0.113 | 0.363 | 3.22 |
| UniMoE-Audio | 0.078 | 0.361 | 3.52 | 0.019 | 0.573 | 3.72 |
| UniFlow-Audio | 0.032 | 0.570 | 3.50 | 0.058 | 0.573 | 3.45 |
| Ming-omni | 0.025 | 0.553 | 3.82 | 0.013 | 0.633 | 3.80 |
| AudioCALM (ours) | 0.020 | 0.668 | 4.02 | 0.011 | 0.672 | 3.95 |
Text-to-sound and text-to-music
| Model | Text-to-Sound | Text-to-Music | ||||||
|---|---|---|---|---|---|---|---|---|
| FAD ↓ | CLAP ↑ | MOS-Q ↑ | MOS-T ↑ | FAD ↓ | CLAP ↑ | MOS-Q ↑ | MOS-T ↑ | |
| Modality-specific baselines | ||||||||
| AudioLDM 2-Large | 5.36 | 0.22 | 3.25 | 3.10 | — | — | — | — |
| TangoFlux | 2.70 | 0.36 | 3.82 | 3.85 | — | — | — | — |
| Stable Audio Open | 4.13 | 0.25 | 3.65 | 3.45 | 2.23 | 0.32 | 3.95 | 3.85 |
| MusicGen-Large | — | — | — | — | 5.28 | 0.19 | 3.65 | 3.45 |
| Unified baselines | ||||||||
| UniAudio | 6.64 | 0.13 | 3.20 | 2.95 | 11.25 | 0.06 | 2.80 | 2.65 |
| UniMoE-Audio | — | — | — | — | 3.71 | 0.22 | 3.80 | 3.60 |
| UniFlow-Audio | 4.22 | 0.35 | 3.62 | 3.80 | 6.39 | 0.15 | 3.45 | 3.25 |
| Ming-omni | 2.46 | 0.27 | 3.85 | 3.60 | 7.98 | 0.07 | 3.25 | 2.92 |
| AudioCALM (ours) | 1.95 | 0.37 | 3.98 | 3.95 | 2.02 | 0.36 | 3.99 | 3.92 |
Ethics
AudioCALM supports zero-shot voice cloning and high-fidelity sound and music synthesis. Deployment requires provenance and consent safeguards against voice-cloning misuse and synthetic-media risks. All audio samples on this page are released solely for the purpose of academic peer review.